
电子健康记录(Electronic health records, EHRs)大部分都以自由文本格式存储。这些数据无法直接用于计算机分析,其潜力仍未得到利用[1]。对于医生来说,从自由文本中手动提取潜在的信息需要较高成本,任务繁重且耗时。因此,迫切需要一种技术来有效帮助研究人员从非结构化文本中准确提取高质量特征,同时理解报告内容并为医生提供决策支持。近年来,随着人工智能的不断发展,自然语言处理 (NLP,Natural Language Processing)技术已成为一种用于解释自由文本的工具。一些研究表明,NLP 模型可以从医疗报告中提取信息,甚至做出决策。然而,之前的NLP模型大多基于卷积神经网络(Convolutional Neural Network, CNN)或循环神经网络(Recurrent Neural Network, RNN), 这些方法可能无法很好地学习远处单词的关系,从而导致解析较长的文本变得困难[2, 3, 4]。近年来,基于变换器的双向编码器表示技术(Bidirectional Encoder Representations from Transformers,BERT) 受到越来越多的关注[5]。然而,BERT需要大量数据进行预训练,公开的预训练模型无法应用于特定领域,例如医疗相关任务。此外,对于长文本和复杂文本,模型性能仍有待提高。

乳腺癌是女性最常见的癌症,也是女性癌症死亡的主要原因[6]。近年来,基于人工智能的乳腺癌研究受到越来越多的关注,特别是在放射学和病理学领域[7]。用于诊断、患者护理和肿瘤学研究的数字健康数据持续呈指数级增长。然而,大多数医疗信息,特别是放射学结果,都以自由文本格式存储,并且这些数据的潜力尚未开发。根据当前从非结构化数据中提取定量数据的术语,例如放射组学(radiomics)、病理组学(pathomics)等,作者提出术语“repomics”(报告组学,report omics)用于从EHRs中提取有价值的特征,例如患者的健康状况和病变的相关特征。本研究中,RadioLOGIC(RadioLogical repOmics driven model incorporatinG medIcal token Cognition)被开发用于理解非结构化放射学报告,提取有价值的repomics特征并对临床诊断进行预测。
掩码语言建模被应用以使得模型可以理解放射学报告的内容。图 1a 和 b 显示了预训练 NLP 模型的基本框架。图1c显示了预训练的学习过程,首先基于所有收集到的乳腺医学相关语料对模型进行预训练,然后模型针对放射学报告的主领域语料进行密集的持续预训练学习,最后该模型针对下游任务进行了微调。 图1d展示了无监督预训练中预测屏蔽词的过程。图2展示了单词和句子的可视化结果,证明了预训练模型学习到了放射学报告中单词之间的相关性。
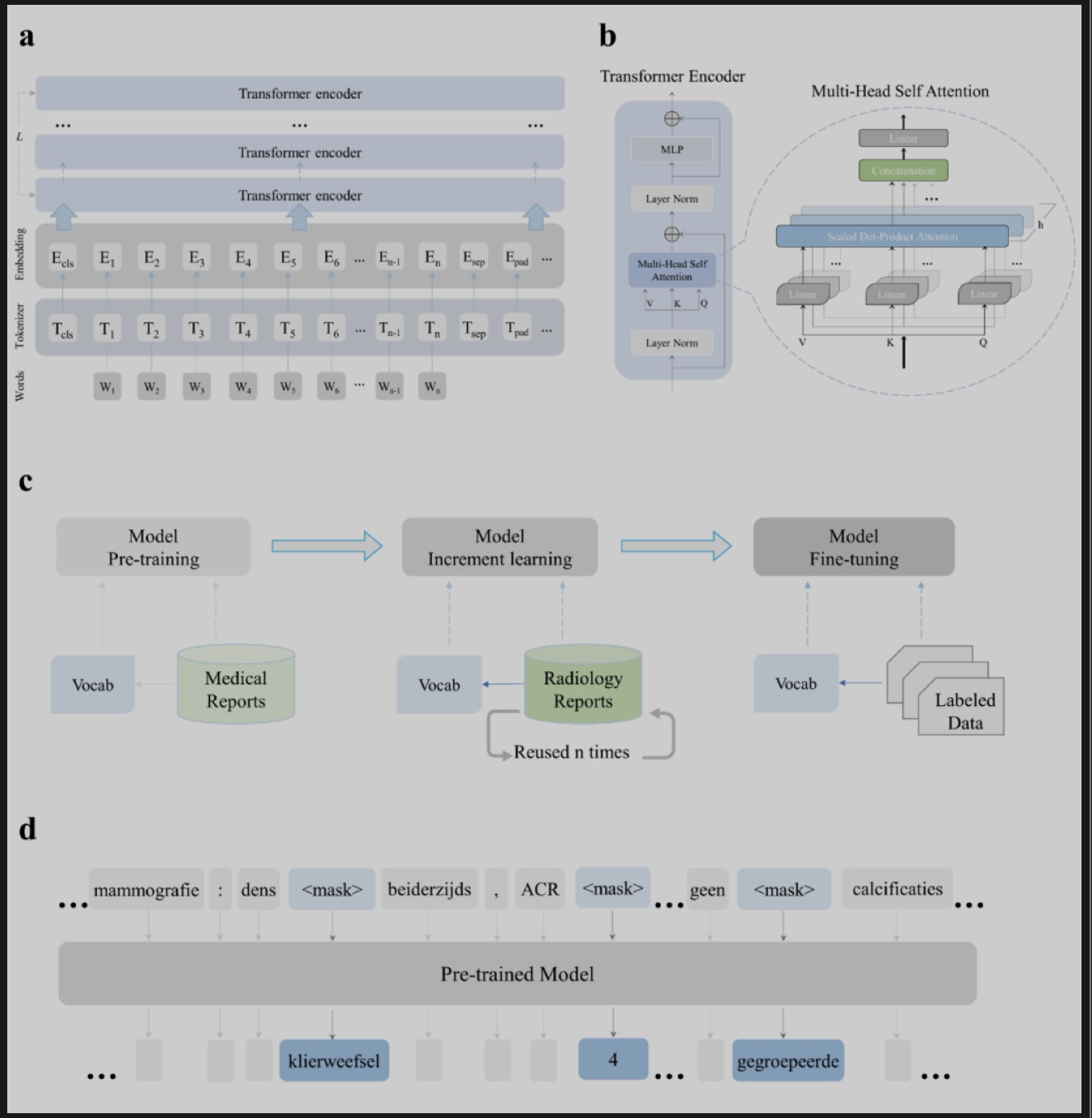
图1. NLP模型预训练的框架和步骤
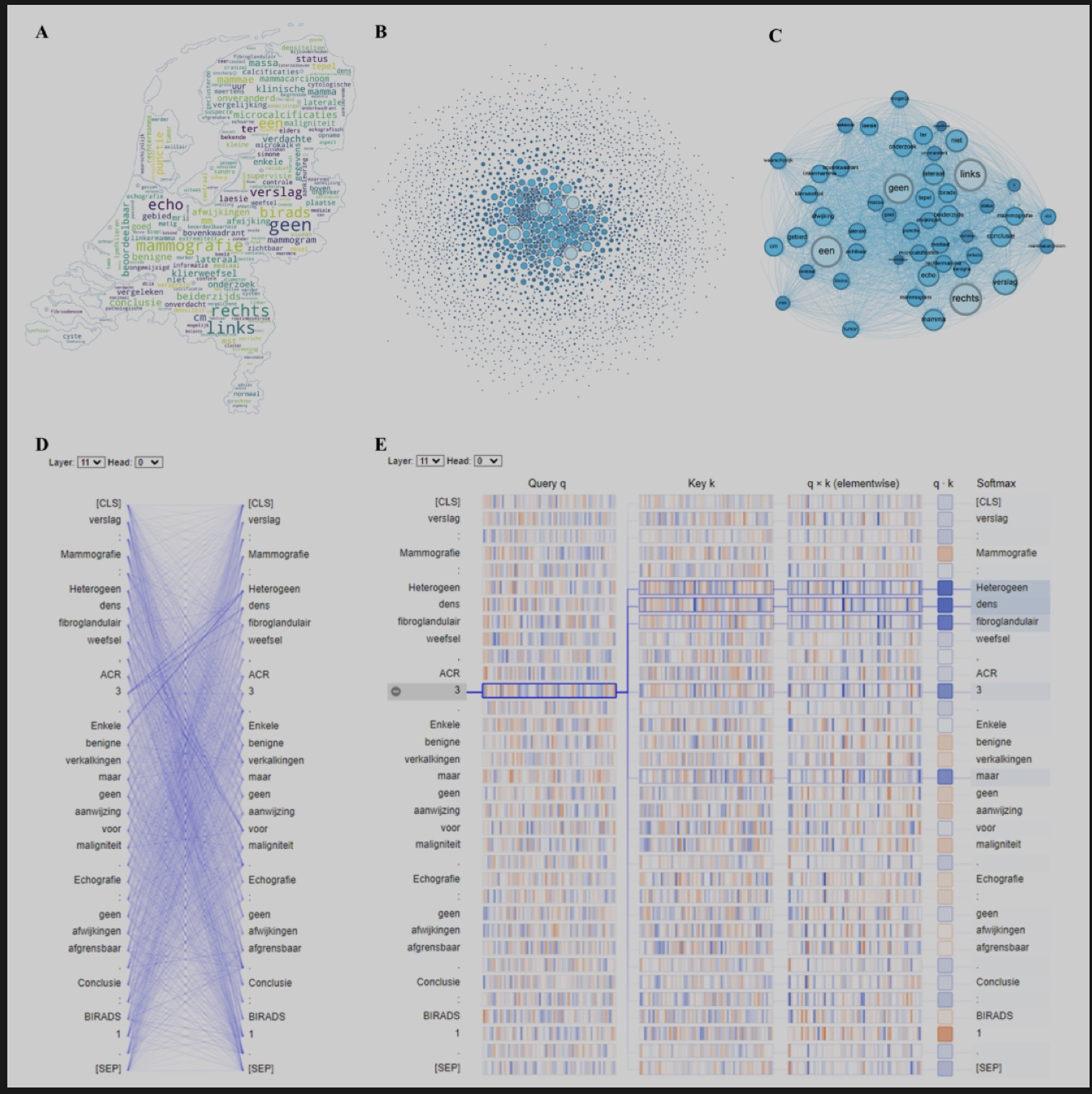
图2. 荷兰语放射学报告中单词和句子的可视化
经过预训练-微调后,研究人员在独立的测试集中对不同模型进行测试。第一个任务是提取repomics特征。为了帮助模型在分类过程中理解报告中每个单词的属性,作者自动为每个单词符记(token)打上属性标签(图3a),并根据解码器预测每个 token 的属性,形成最终的模型RadioLOGIC(图3b)。如表1所示,结合医疗令牌认知后,我们的模型的性能得到显着且实质性的进一步提升,平均准确度为0.934 [0.920, 0.948],平均F1-Micro为0.937 [0.922, 0.949], 平均F1-Macro为0.868 [0.842, 0.892],平均 F1 加权为0.934 [0.919, 0.948](CNN-ATT/RNN-ATT/RadioBERT/RadioBERTw vs RadioLOGIC,所有 p 值<0.001)。
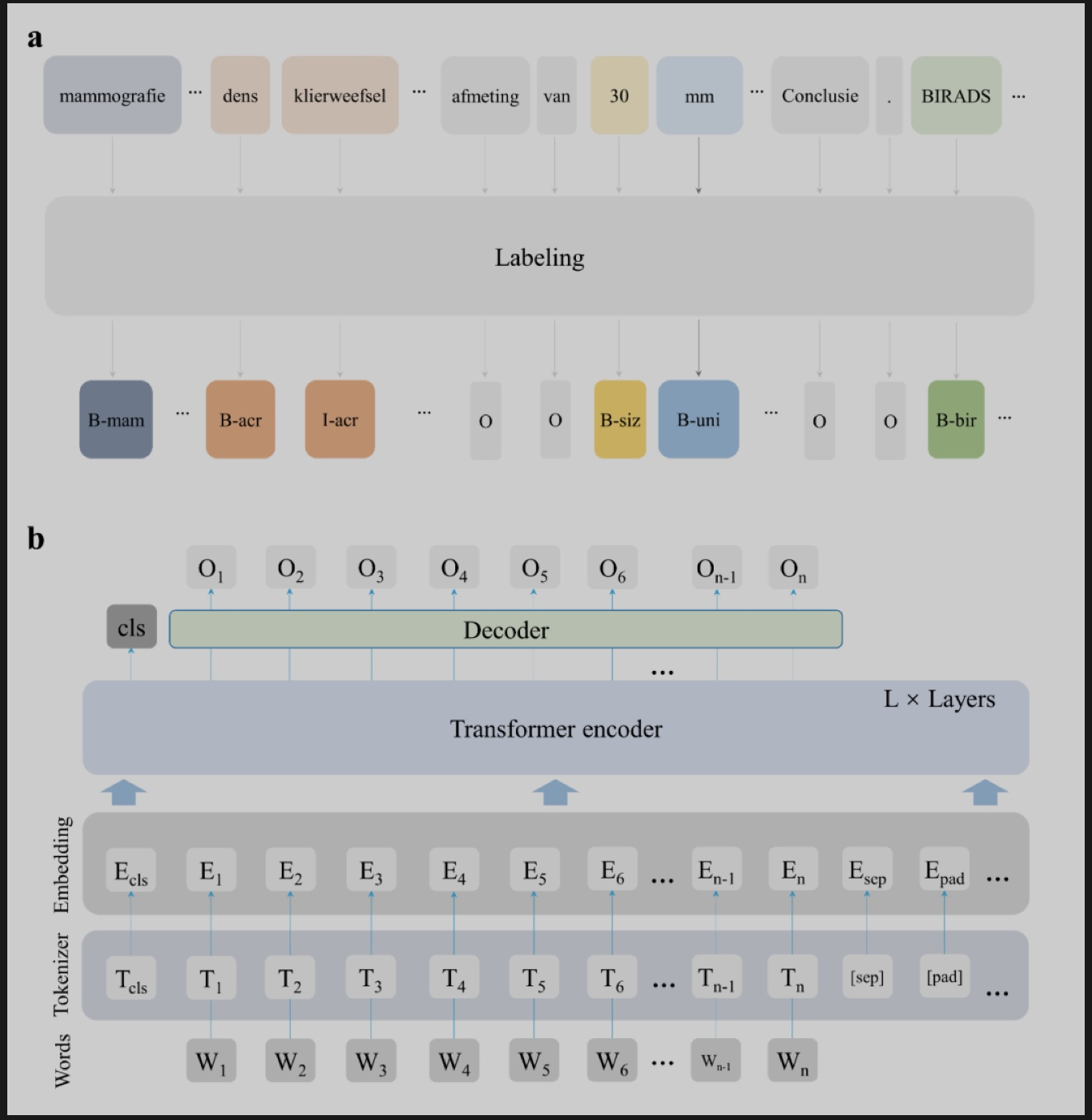
图3. RadioLOGIC模型详情
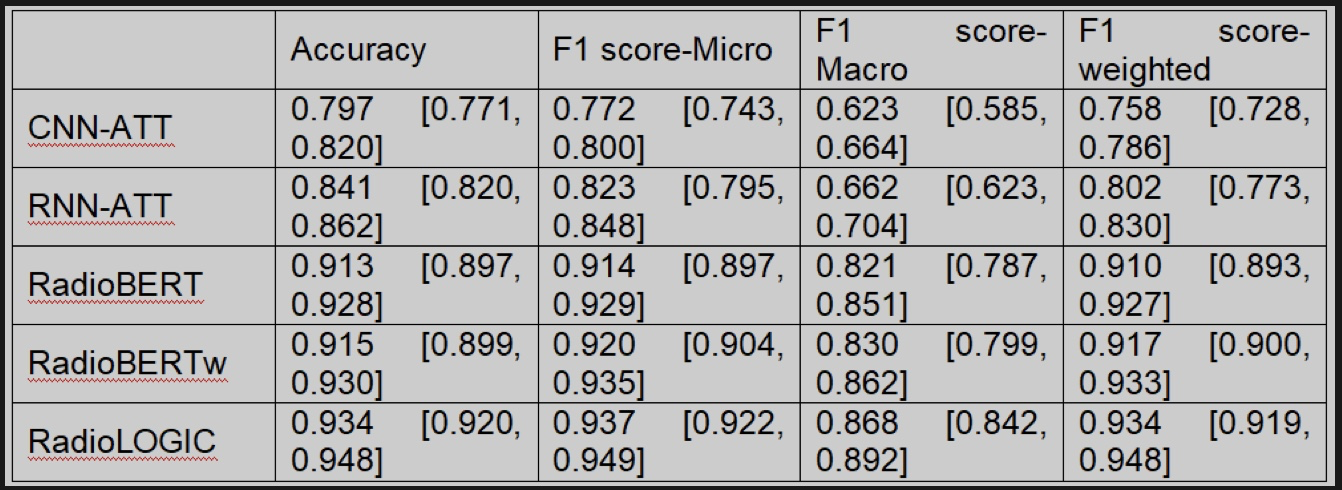
Note: Values in brackets are 95% confidence intervals. CNN, convolutional neural networks. RNN, recurrent neural networks. ATT, Attention mechanism. BERT, bidirectional encoder representations from transformers. RadioBERT, original Radiology BERT. RadioBERTw, original RadioBERT with weighted loss. RadioLOGIC, RadioLogical repOmics driven model incorporatinG medIcal token Cognition.
在这个任务中,研究人员屏蔽了报告中已有的BI-RADS(Breast Imaging-Reporting and Data System)分数并将其用作预测标签,然后使用RadioLOGIC来预测BI-RADS分数。图 4a 和 b 显示了在独立测试队列中预测 BI-RADS 评分的混淆矩阵。结果显示RadioLOGIC模型可以预测 BI-RADS 分数,准确度高达 0.850 [0.832, 0.869],F1 加权得分为 0.838 [0.817, 0.859]。迁移学习提高了模型的性能,准确度为 0.906 [0.890, 0.921] (p<0.001),F1 加权得分为 0.903 [0.887, 0.919] (p<0.001)。
图 4c 和 d展示了NLP模型直接根据放射学报告预测病理结果的表现。RadioLOGIC 可以直接从非结构化放射学报告预测病理结果,AUC 为 0.912 [0.866, 0.954],优于目前广泛使用的结合 RNN 和注意力机制的 NLP 模型 (RNN-ATT, 0.887 [0.832, 0.937])(RNN-ATT 与 RadioLOGIC ,p<0.001)。结合迁移学习的 RadioLOGIC 的AUC为 0.945 [0.908, 0.977],优于没有迁移学习的 RadioLOGIC。

图3. 下游任务的预测结果
